-
Chapter 2-1. Practical Time Series Analysis (실전 시계열 분석)Extra study/Time series Analysis 2022. 10. 25. 01:37728x90
안녕하세요, 빼리냐옹이🐈 입니다 :)
이번에는 Practical Time Series Analysis Chapter 2를 다뤄볼 예정이며,
Chapter 2는 내용이 다소 많아 본문이 길어지는 것을 고려하여 Part를 나눠서 작성해보고자 합니다.'Practical Time Series Analysis'

Chapter 2. 시계열 데이터의 발견 및 다루기
Intro. 해당 챕터에서는 시계열 데이터 전처리 과정에서 발생할 수 있는 문제를 다룬다.
데이터 분석 중 타임스탬프에 의한 특정 어려움이 있으며, 타임스탬프를 다루는 과정에서 가장 중요한 단계는
데이터를 정리하고 제대로 처리하는 것으로 해당 챕터에서는 시계열 데이터를 찾고 정리하는 유용한 기술을 소개할 예정- 시계열 데이터를 찾고 정리하는 유용한 기술 소개
- 온라인 저장소에서 시계열 데이터 탐색
- 시계열을 고려하지 않고 수집된 데이터에서 시계열 데이터를 발견하고 준비하는 방법
- 일반적인 난제, 특히 타임스탬프가 초래하는 어려움을 다루는 방법
2-1. 시계열 데이터는 어디서 찾는가
Intro. 다양한 자료들이 존재하며, 어느 자료가 적합한지는 다음 두 목적에 따라 달라진다.
- 학습과 실험 목적에 맞는 데이터 셋 탐색
→ 일반적으로 캐글과 같은 대회용 데이터셋, 저장소 데이터셋이 목적에 부합함 - 시간 지향적인 형태가 아닌 데이터에서 시계열 데이터 생성
→ 우리가 원하는 시계열 데이터를 만들기 위해 타임스탬프가 찍힌 데이터를 식별해 시계열로 변환하고,
다듬고, 또 다른 타임스탬프가 찍힌 데이터와 결합해 시계열 데이터를 만들기 위한 방법을 고민해야 함
→ 발견된 시계열 (found time series) : 야생 (일상)에서 발견된 데이터셋을 발견된 시계열
2-1-1. 미리 준비된 데이터셋
Intro. 분석 및 모델링 기법을 학습하는 최고의 방법은 데이터셋에 기법을 직접 적용해보고, 각 기법이 구체적 목표에 도달하는데
어떤 도움을 주는지 확인하는 것이며, 이때 준비된 (전처리된) 데이터셋을 선택하는 것이 유용함1. UCI 머신러닝 저장소 (UCI Machine Learning Repositorty) : 약 80개의 다양한 시계열 데이터셋 보유
- 결근 데이터셋 (https://perma.cc/8E7D-ESGM)
- 해당 데이터는 연도정보가 없어 문제를 파악하기 위한 기준을 정해야 함
- 결근일수 : 단위시간 or ID별로 종합
→ 전자는 단일 시계열을 얻고, 후자는 타임스탬프가 중첩된 시계을 여러 개 생성
→ 이때 우리가 풀고자 하는 문제가 무엇인가에 따라 기준의 선택이 달라짐
- 해당 데이터는 연도정보가 없어 문제를 파악하기 위한 기준을 정해야 함
- 오스트레일리아 수화 데이터셋 (https://perma.cc/TC5E-Z6H4)
- 닌텐도 파워글러브로 수화를 수신해 기록한 데이터로 가로로 넓은 csv파일로 저장 됐으며,
폴더에 포함된 각 파일명은 특정 수화 동작을 의미함. 즉 각 파일은 한 번의 측정에 매핑 - 이 데이터셋은 레이블링되지 않고 타임스탬프도 없지만, 시계열 데이터로 볼 수 있음
→ 사건이 실제로 발생한 실제 시점이 아니여도, 시간의 경과를 시간축으로 생각할 수 있기 때문
→ 측정된 시간보다연속성을 가진다는 점이 중요
→ 단, 사건의 정렬된 순서와 사건의 측정 간격이 일정한지 검증해야 함
- 닌텐도 파워글러브로 수화를 수신해 기록한 데이터로 가로로 넓은 csv파일로 저장 됐으며,
- 데이터를 다루는 난관
- 불완전한 타임스탬프
- 데이터에 수평이나 수직이 될 수 있는 시간축
- 시간에 대한 다양한 관념
2. UEA 및 UCR 시계열 분류 저장소 (https://perma.cc/56Q5-YPNT)
- 요가 동작 분류 작업 (https://perma.cc/U6MU-2SCZ)
- 목적 : 각 요가 동작의 분류
- csv 맨 좌측 열은 레이블, 나머지 열은 시간의 순서 (좌측에서 우측 방향으로 시간의 흐름 해석)
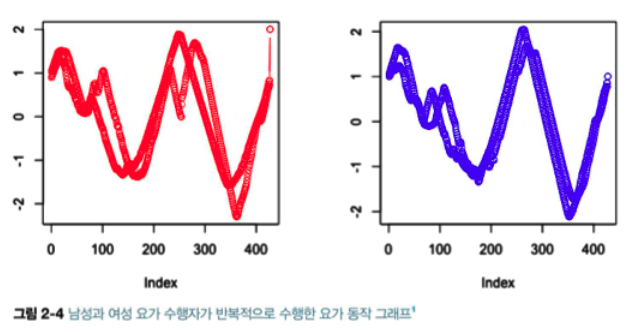
x축은 시간에 대한 명확한 레이블은 없지만 단위시간을 사용했으며, x축이 균등하게 퍼져있음이 중요한 포인트 - 와인 데이터셋 (https://perma.cc/Y34R-UGMD)
- 스펙트럼 (spectrum) : 빛의 파장 대 강도에 대한 그래프로 시계열과 상관 없어 보이지만,
x축은 유의미한 방식으로 정렬 돼 있고 그 거리는 구체적 의미를 가져 시계열 분석에 적용할 수 있음
→ 파장 등과 같이 x축의 순서로 얻는 추가정보는 시간적 요소는 없지만, 데이터가 일련의 정렬된 형태를 띠므로
시계열 아이디어를 적용할 수 있음
- 스펙트럼 (spectrum) : 빛의 파장 대 강도에 대한 그래프로 시계열과 상관 없어 보이지만,

곡선의 정점은 높은 흡수율을 보인 지역의 파장을 의미하며, 파장은 x축을 따라 간격이 균등하고, 흡수율을 나타내는 y축도 선형적인 척도를 가짐 cf. 일변량(univariate) 시계열과 다변량(multivariate) 시계열
- 일변량 시계열 : 시간에 대해 측정된 변수가 하나만 있는 경우
- 다변량 시계열 : 각 타임스탬프에서 측정된 변수가 여러 개인 경우
3. 정부 시계열 데이터셋
→ 정부 데이터셋은 탐구적 분석 및 시각화 목적으로만 사용하는 것이 좋음
그 이유는 매우 복잡한 문제를 다루는 것이 주이기 때문에 이를 통해 무언가 배우는 것은 어려우며,
많은 전문가들도 실업률 예측 등 예측을 성공한 경우가 드물기 때문
ex. NOAA 국립환경정보센터, 미국 노동 통계국, 미국 질병통제예방센터, 세인트루이스 연방준비은행
2-1-1. 발견된 시계열
Intro. 발견된 시계열은 야생 (일상)에서 직접 수집한 시계열 데이터
- 발견된 시계열의 예시
- SQL 데이터베이스 내 특정 고객과의 거래에 대한 시계열 데이터
- 기업의 하루 총 거래량, 여성 고객의 주당 지출 총액 데이터
- 다변량 시계열 데이터 (3가지 지표)
→ 18세 미만 고객 주당 지출 총액, 65세 이상 여성 고객 주당 지출 금액, 회사가 광고에 쓴 주당 지출 총액
- 타임스탬프가 찍힌 이벤트 기록 (데이터베이스에서 타임스탬프를 확인할 수 있는 예시)
- 파일에 접근한 시간을 기록하기만 해도 시계열 구성 가능
- 임의시점과 그 이후 시점의 타임스탬프로 시간의 변화량을 모델링하여 시간에 대한 시간축과 시간 변화량에 대한
값축으로 시계열 구성 가능 - 변화량의 일부를 합해 더 큰 기간에 대한 평균, 총합을 산출하여 각각을 개별적으로 기록 가능
- 시간을 대체하는 ‘시간이 없는’ 측정
- 데이터셋의 숨은 논리로 시간이 설명되는 경우 : 알려진 비율에 따라 센서가 수축하듯 어떤 실험 매개변수에 의해
간격이 발생하면 ‘간격 대 값’으로 데이터를 생각할 수 있음
→ 변수 중 하나를 시간에 대응할 수 있다면 시계열이 있다고 봄 (cf. 와인 스펙트럼 파장)
- 데이터셋의 숨은 논리로 시간이 설명되는 경우 : 알려진 비율에 따라 센서가 수축하듯 어떤 실험 매개변수에 의해
- 물리적 흔적
- 현대에는 물리적으로 생성된 흔적을 디지털 형태로 저장하며 이는 이미지 파일, 데이터베이스에 한 필드의 단일 벡터와 같은 형태로 저장됨 (시계열)
공감은 제가 공부하고 공유하며 소통하는 원동력이 됩니다.
해당 글이 도움이 되셨다면 공감 부탁드립니다 ☺️728x90'Extra study > Time series Analysis' 카테고리의 다른 글
Chapter 1. Practical Time Series Analysis (실전 시계열 분석) (0) 2022.10.23 - 시계열 데이터를 찾고 정리하는 유용한 기술 소개